Datenbankansicht¶
Übersicht¶
Die DATAMIMIC Datenbankansicht ist der zentrale Arbeitsbereich für metadatenbasierte Artefaktgenerierung aus relationalen Datenbanken.
Sie kombiniert Scope-Auswahl, Abhängigkeitsplanung, Weighting-Vorbereitung, Schema-Drift-Sichtbarkeit und Erstellungsaktionen in einer Ansicht.
Ab 3.1.0 erfolgt die Generierung eines DATAMIMIC-Modells aus Datenbank-Metadaten über die Datenbankansicht und nicht mehr über den Editor-Dateifluss.
Ab 3.2.0 ist dieser Ablauf in dedizierten Database-Workbench-Tabs (Planning, Weighting, Schema history) mit expliziten Create-Aktionen organisiert.
Reifegrad und Erwartungsmanagement¶
Die metadatenbasierte Modellerstellung in der Datenbankansicht wird aktiv weiterentwickelt.
Betrachte erzeugte Artefakte und Empfehlungen als starken Startpunkt, aber nicht als finales, produktionsfertiges Ergebnis.
- Manuelle Prüfung und Nachjustierung bleiben erforderlich, insbesondere bei komplexen Relationships und großen produktiven Schemata.
- Empfehlungsergebnisse hängen von Metadatenqualität, Beziehungsqualität und projektspezifischen Maskierungsanforderungen ab.
- Nutze explizite Steuerungsmöglichkeiten (zum Beispiel manuelle PII-Entscheidungen auf Spaltenebene, inklusive Spalten explizit als 100% PII zu markieren), um generierte Defaults zu überschreiben oder zu verschärfen.
Geplante Ausbaufelder sind:
- erweiterte Override-Möglichkeiten für Empfehlungsentscheidungen,
- stärkerer Support für projekt- und umgebungsspezifische Aliases (Generatoren, Entity-Attribute, PII-Feld-Aliases),
- unterstützte Voranonymisierungs-Flows auf Basis hochgeladener Spezifikationen für große Metadatenstrukturen.
Vorbedingungen¶
- Erstelle eine Datenbank-Umgebung.
- Führe Metadaten scannen für diese Umgebung aus.
- Wenn Metadaten veraltet oder inkonsistent sind, nutze Metadaten zurücksetzen und danach erneut Metadaten scannen.
Dieser Reset/Rescan-Flow ist der unterstützte Weg, um Modell-Eingaben nach Schemaänderungen zu aktualisieren.
Unterstützte relationale Datenbanken¶
- PostgreSQL
- Oracle
- Weitere Systeme, sofern in deiner Instanz aktiviert
Zentrale Funktionen¶
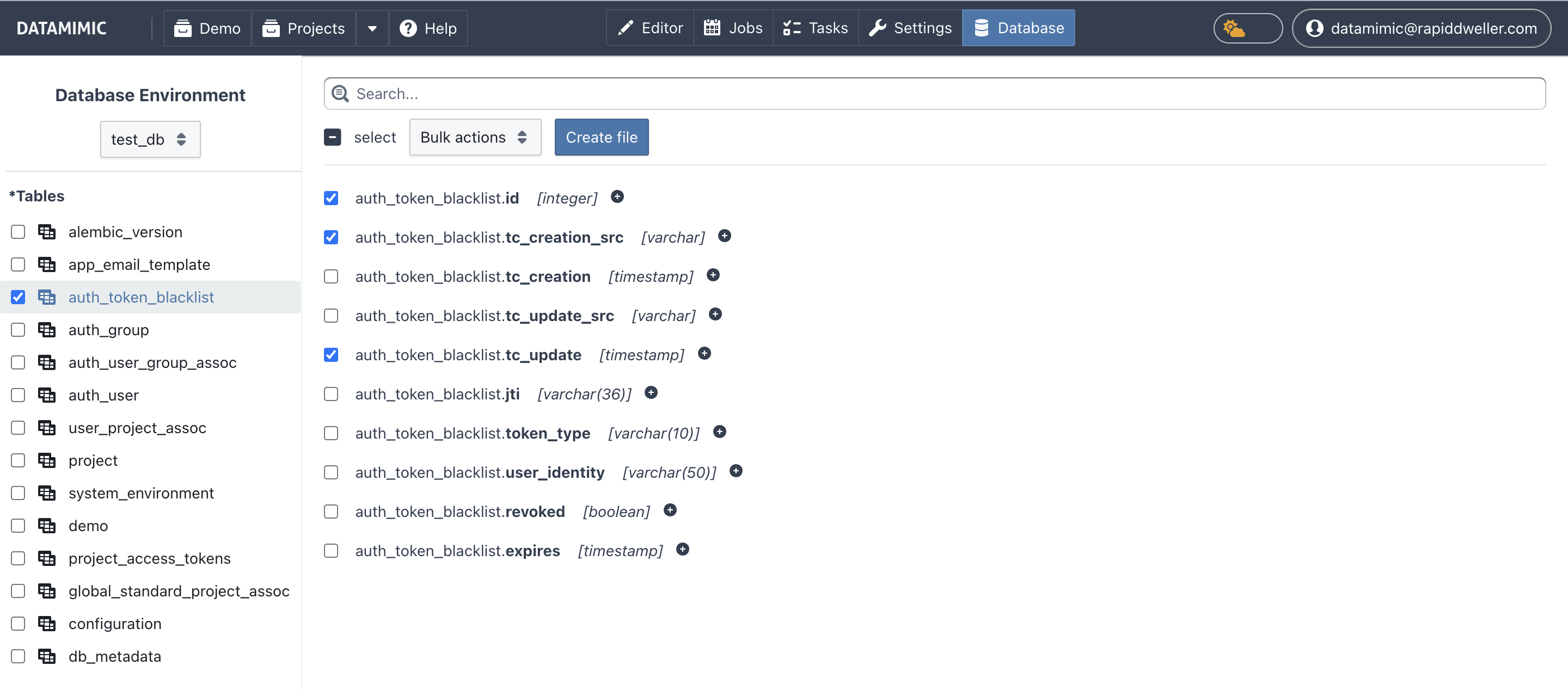
Transparenz für Umgebung, Schema, Tabellen und Spalten¶
- Wähle eine Umgebung aus dem Dropdown.
- Durchsuche Tabellen und Spalten mit klarer Strukturansicht.
- Nutze schemaqualifizierte Tabellennamen (wo verfügbar), um Mehrdeutigkeiten zu vermeiden.
- Nutze den Schema-Filter in der Sidebar, um große Tabellenlisten schnell einzugrenzen.
Metadaten-Scan-Scope (alle zugreifbaren Schemata)¶
- Metadaten scannen nutzt die Datenbank als Scope und reflektiert alle Schemata, auf die der konfigurierte Benutzer zugreifen kann.
- Das in der Umgebung konfigurierte Schema wird als Default-Schema für nicht qualifizierte Namen verwendet.
- Nicht zugreifbare Schemata werden im Best-Effort-Verhalten übersprungen und im Task-Log vermerkt.
- Der größere Metadaten-Scope verbessert die Erkennung von schemaübergreifenden Beziehungen für Plan Subset und metadatenbasierte Artefakt-Generierung.
Subset-Auswahl und Bulk-Aktionen¶
- Wähle Tabellen und Spalten für dein Modell-Subset.
- Nutze Alle auswählen / Alle abwählen, um Selektionen schnell zu setzen oder zurückzusetzen.
- Nutze Bulk-Aktionen, um Skripte/Generatoren konsistent auf ausgewählte Spalten anzuwenden.
Plan Subset (Relationship Closure)¶
- Führe Plan Subset aus, um Tabellenbeziehungen und Foreign-Key-Abhängigkeiten zu analysieren.
- Übernimm die vorgeschlagene Closure, damit zusätzlich erforderliche Tabellen für referenziell konsistente Generierung einbezogen werden.
- Nach der Planung zeigt die Tabellenliste in der Sidebar nur noch IN SCOPE-Tabellen.
- Nutze Reset im Planning-Schritt, um den aktiven Subset-Snapshot zu invalidieren und die ursprünglichen
requested_rootswiederherzustellen. - Solange der Subset-Snapshot aktiv ist, bleiben globale Tabellenaktionen Alle auswählen / Alle abwählen absichtlich gesperrt.
- Die Synthetic-DATAMIMIC-Modellerstellung ist erst aktiv, nachdem Plan Subset ausgeführt und geprüft wurde.
PII-Vorauswahl¶
Die Datenbankansicht unterstützt eine Vorauswahl für Spalten, die wahrscheinlich PII enthalten.
Du kannst diese Auswahl vor der Modellgenerierung prüfen und anpassen.
Database-Workbench-Tabs¶
- Planning: Subset-Closure planen und Abhängigkeiten vor der Generierung validieren.
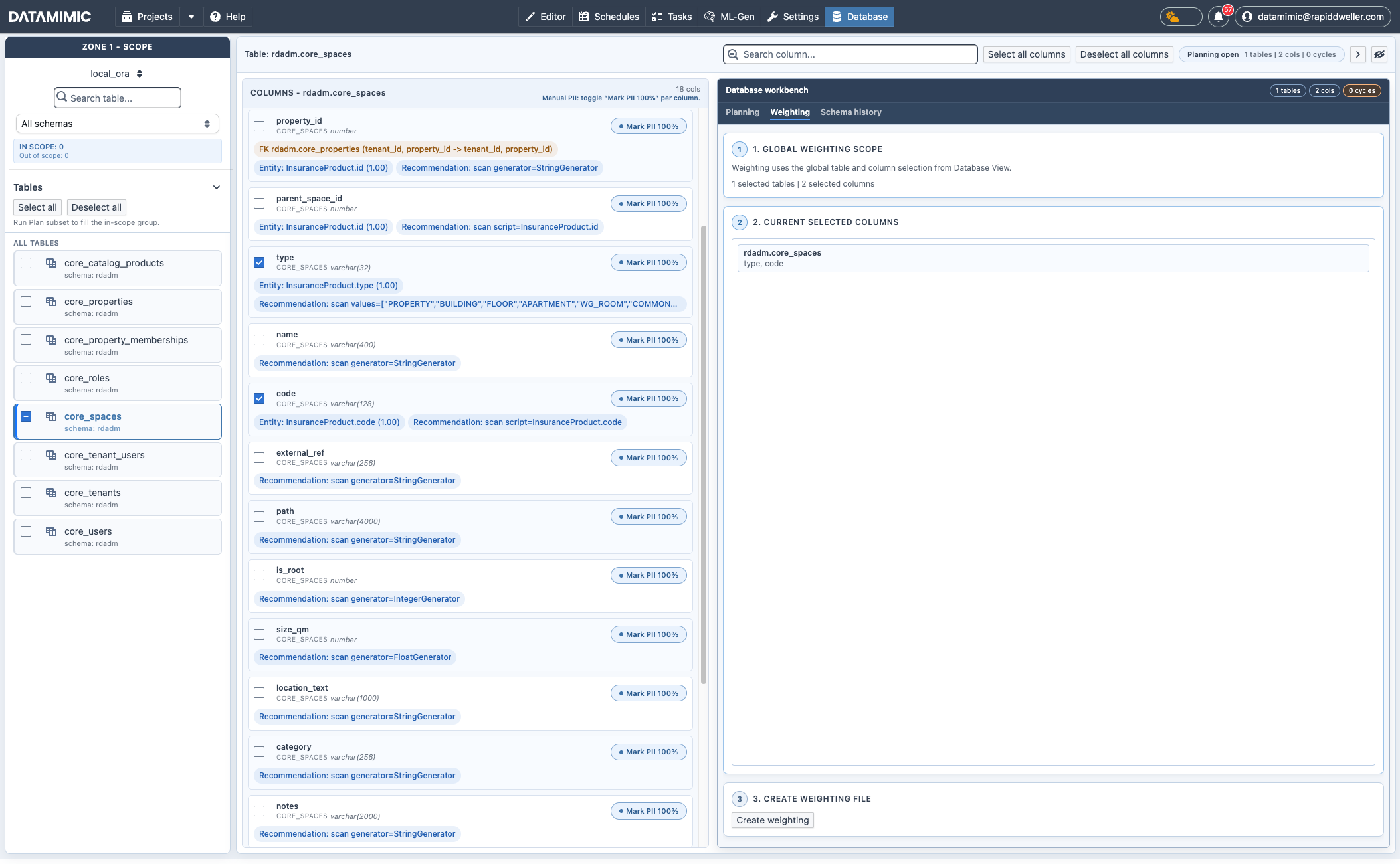
- Weighting: Weighting-Scope aus gewählten Tabellen/Spalten aufbauen und Weighting-Dateien erzeugen.
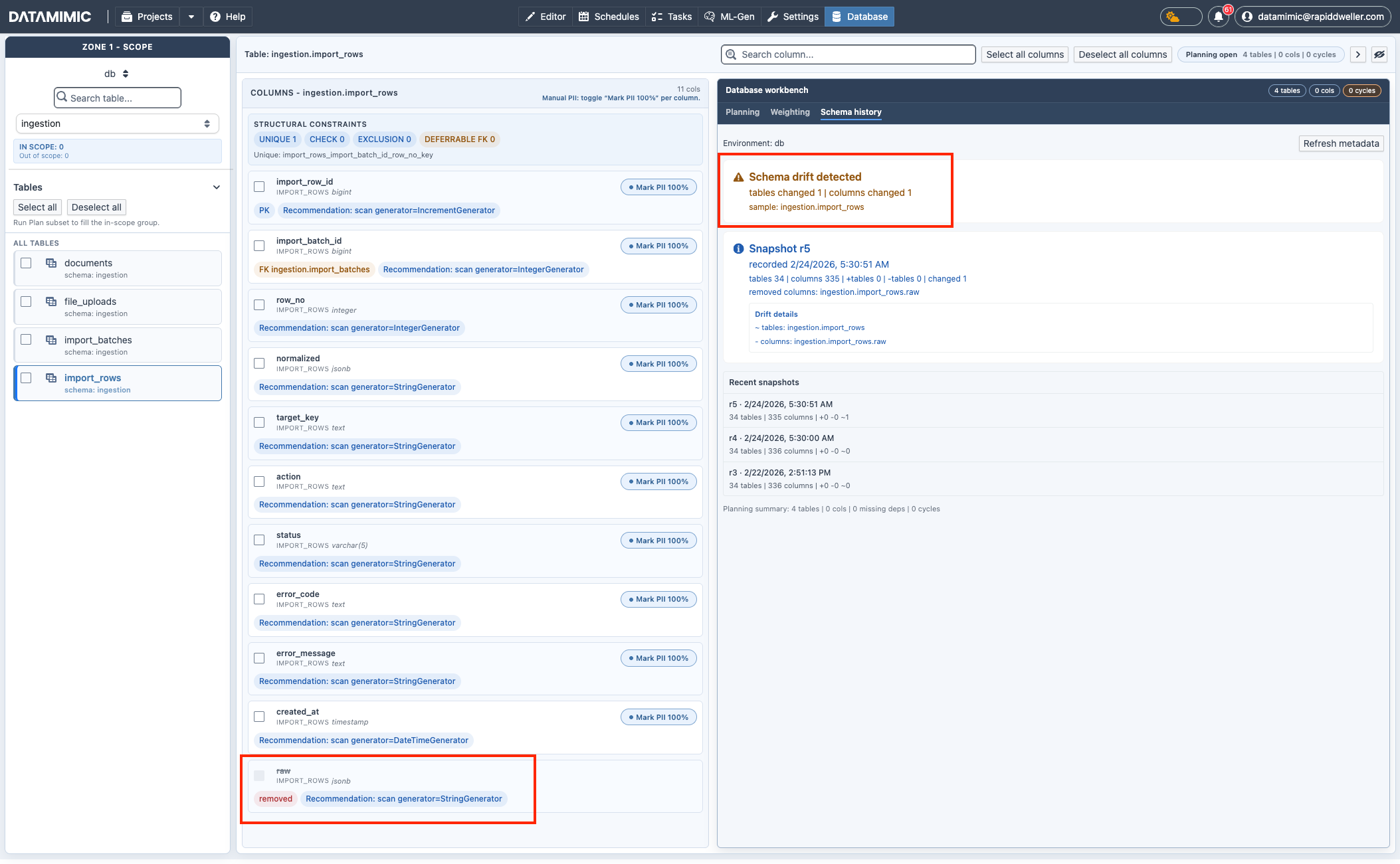
- Schema history: Schema-Drift und Snapshot-Änderungen der Metadaten nachvollziehen.
Artefakte aus dem Planning-Tab erzeugen¶
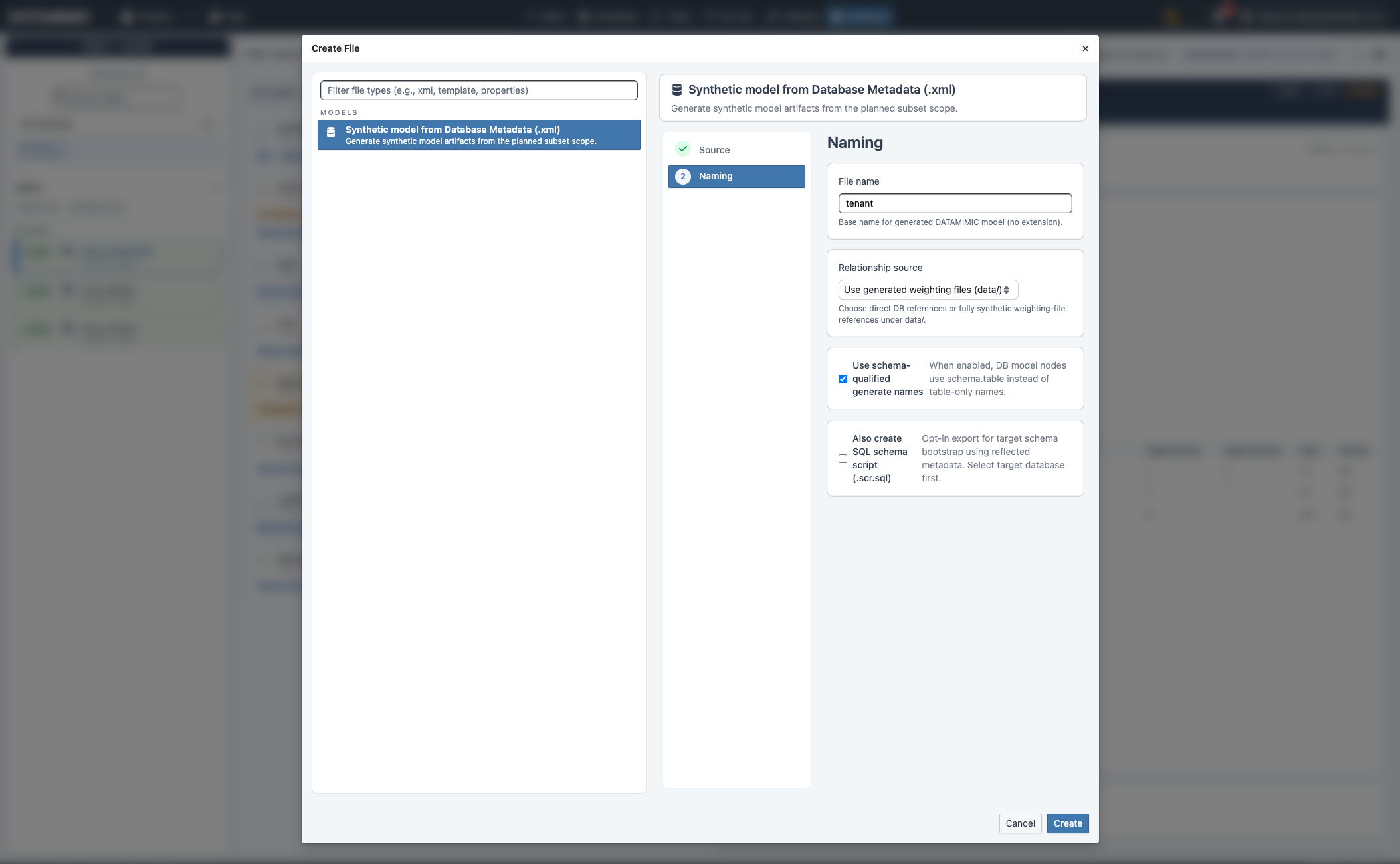
Nutze die Aktionsbuttons im Bereich Generate artifacts:
- Create Synthetic: synthetisches Modell-Artefakt aus geplantem Subset.
- Create Anonymize: anonymisierungsorientiertes Modell-Artefakt mit Source-/Target-DB-Einstellungen.
- Create ML: ML-Trainingsmodell-Artefakt aus geplantem Subset.
Relationship-Quelle für Referenzen¶
Beim Erstellen eines datenbankbasierten Modell-Artefakts kannst du steuern, wie <reference>-Werte aufgelöst werden:
| Modus | Verwenden, wenn | Einschränkungen |
|---|---|---|
database |
Parent-Key-Reuse aus echten Source-DB-Daten erfolgen soll (source + sourceType) |
In allen DB-Builder-Modes unterstützt. |
weighting_files |
Vollsynthetische FK-Auswahl über Weighting-Dateien unter data/ gewünscht ist (.wgt.csv / .wgt.ent.csv) |
Nur für Modellerstellung mit builder_mode=datamimic; .wgt.csv ist auf ein Ziel-Feld begrenzt. |
Für die genaue <reference>-Semantik (Single/Composite-Mappings, <field>, sourceKey, Priorität) siehe Datendefinitionsmodell - Fortgeschrittene Elemente.
Typische erzeugte <reference>-Ausgaben:
1 2 3 4 | |
1 2 3 4 | |
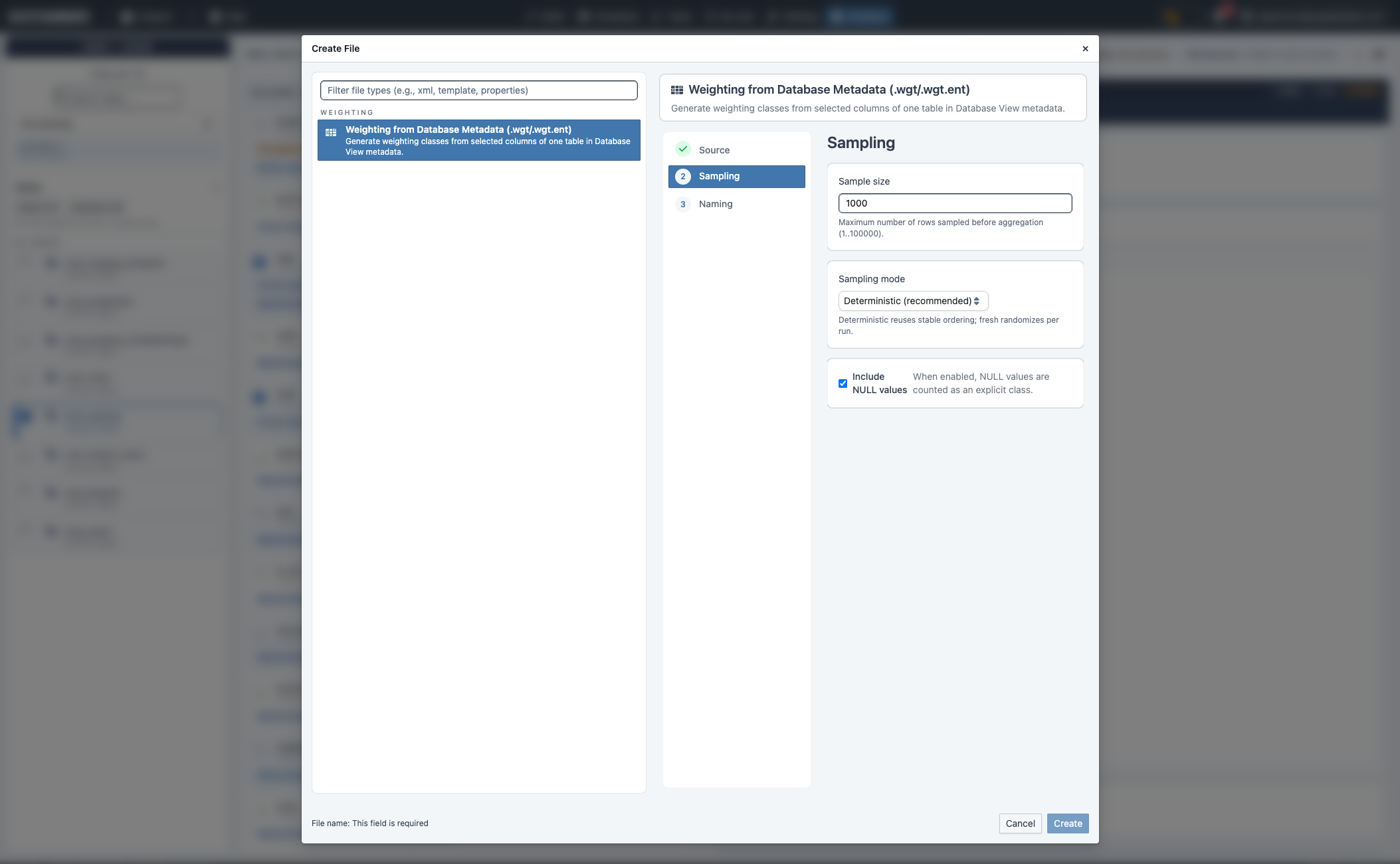
Weighting-Dateien aus Metadaten erstellen (3.2.0)¶
- Wechsle zu Database workbench → Weighting, um Weighting-Artefakte aus Metadaten zu erzeugen.
- Wähle genau eine Tabelle und mindestens eine Spalte:
- 1 ausgewählte Spalte →
.wgt.csv - 2+ ausgewählte Spalten →
.wgt.ent.csv - Sampling-Optionen:
sample_size(Standard:1000)sampling_mode:deterministicoderfreshinclude_nulls: NULL-Werte als explizite Klasse ein-/ausschließen- Der Weighting-Wert wird als normalisierter Faktor (
count / sampled_rows) gespeichert, damit Verteilungen zwischen unterschiedlichen Sample-Größen vergleichbar bleiben.
Schema History und Drift-Sichtbarkeit¶
- Nutze Database workbench → Schema history, um Metadaten-Drift zwischen Snapshots zu prüfen.
- Die Drift-Details (geänderte Tabellen/Spalten) helfen zu entscheiden, ob Subset-Planung oder Neugenerierung notwendig ist.
Nach der Auswahl deines Subsets:
Create-Synthetic-Modell¶
- Führe Plan Subset aus, prüfe Abhängigkeiten und übernimm die Relationship-Closure.
- Klicke Create Synthetic.
- Vergib den Modell-Dateinamen.
- Konfiguriere Relationship-Quelle und optional schemaqualifizierte Namen.
- Aktiviere optional SQL-Schema-Skript-Export (
.scr.sql), wenn benötigt. - Prüfe und erstelle.
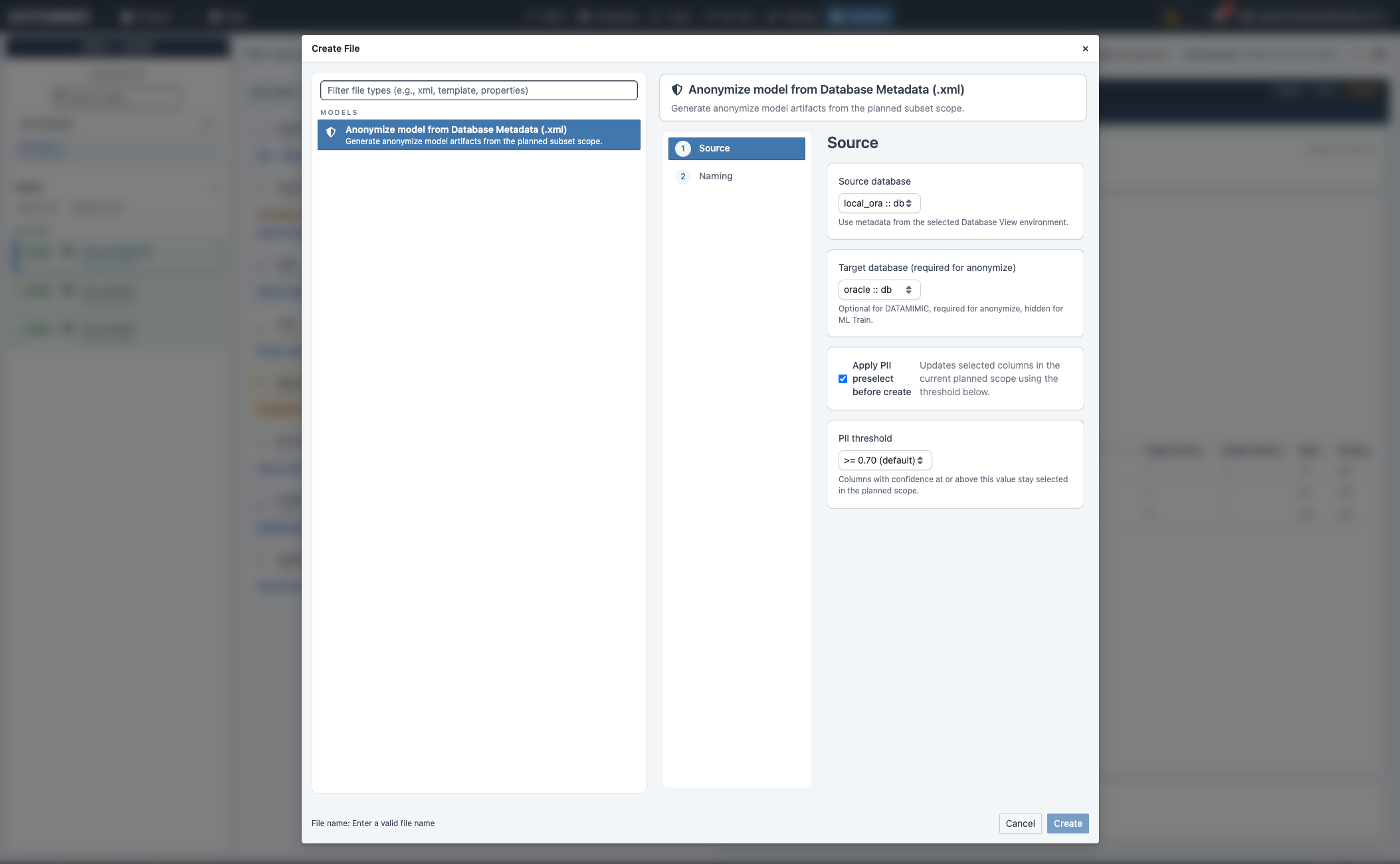
Create-Anonymize-Modell¶
- Führe Plan Subset aus und prüfe den ausgewählten Scope.
- Klicke Create Anonymize.
- Setze Source- und Target-Datenbank.
- Optional: PII-Preselect und Threshold anwenden.
- Namen vergeben und erstellen.
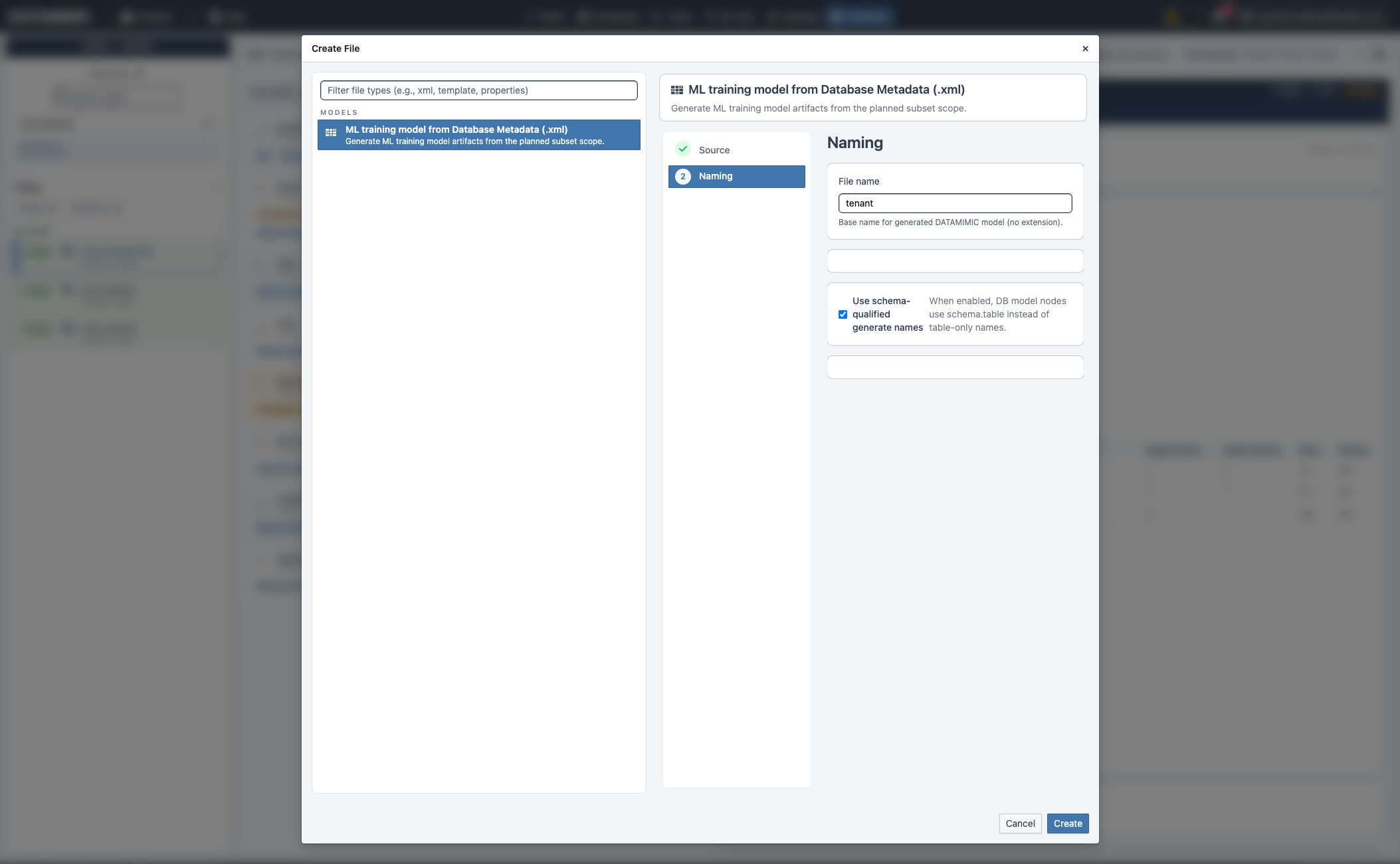
Create-ML-Modell¶
- Führe Plan Subset aus und prüfe den ausgewählten Scope.
- Klicke Create ML.
- Prüfe Source und vergib Dateinamen.
- Aktiviere optional schemaqualifizierte Namen.
- Prüfe und erstelle.
Von Create ML zur ML-Generator-Ansicht¶
Nach dem Erstellen von ML-Modell-Artefakten in der Datenbankansicht:
- Führe das erzeugte DSL-Modell aus, damit
<ml-train>ML-Generator-Versionen trainiert und persistiert. - Öffne die ML-Generator-Ansicht.
- Wähle das erzeugte Modell und prüfe KPI-/Qualitätsstatus.
- Wähle eine Version und setze sie bei Freigabe als Default.
- Nutze das Modell in der DSL mit
source="ml://<model_name>".
Bei großen Trainings-Scopes kann der Lauf deutlich länger dauern und mehr Runtime-Ressourcen benötigen (CPU/RAM und je nach Setup auch GPU-Worker).
Weighting-Datei erstellen¶
- Wähle genau eine Tabelle und die gewünschten Spalten in der Datenbankansicht.
- Öffne den Weighting-Tab.
- Klicke Create weighting.
- Setze Dateiname und Sampling-Optionen (Sample-Größe, Modus, NULL-Handling).
- Prüfe und erstelle:
.wgt.csvfür Single-Column-Weighting.wgt.ent.csvfür Multi-Column-Entity-Weighting
Für einen vollständigen Ablauf siehe Automatisches Generieren eines Modells aus einer Datenbank.