Automatisches Generieren eines Modells aus einer Datenbank¶
Die Datenbankansicht ist der zentrale Arbeitsbereich, um Modell- und Weighting-Artefakte aus gescannten Datenbank-Metadaten zu erstellen.
Ab 3.2.0 ist der Ablauf in den Database-Workbench-Tabs (Planning, Weighting, Schema history) mit dedizierten Create-Aktionen organisiert.
Schritte¶
1. Stelle sicher, dass Du ein Projekt hast¶
Starte mit einem vorhandenen Projekt oder erstelle ein neues (zum Beispiel ein leeres Projekt).
2. Konfiguriere eine Datenbank-Umgebung¶
- Öffne Settings → Umgebungen.
- Füge eine Datenbank-Umgebung hinzu oder bearbeite eine bestehende.
- Stelle sicher, dass Zugangsdaten und Verbindung korrekt sind.
3. Scanne Metadaten¶
- Führe Metadaten scannen für die ausgewählte Umgebung aus.
- Sind Metadaten veraltet, führe zuerst Metadaten zurücksetzen aus und scanne erneut.
- Der Metadaten-Scan umfasst alle zugreifbaren Schemata der ausgewählten Verbindung.
4. Öffne die Datenbankansicht und plane dein Subset¶
Arbeite in der Datenbankansicht von links nach rechts:
- Zone 1 - Scope: Umgebung, Schema-Filter und Tabellen wählen.
- Spalten-Panel: Spalten prüfen und auswählen.
- Database workbench → Planning: Plan subset ausführen, Abhängigkeits-Closure validieren und Subset-Preflight prüfen.
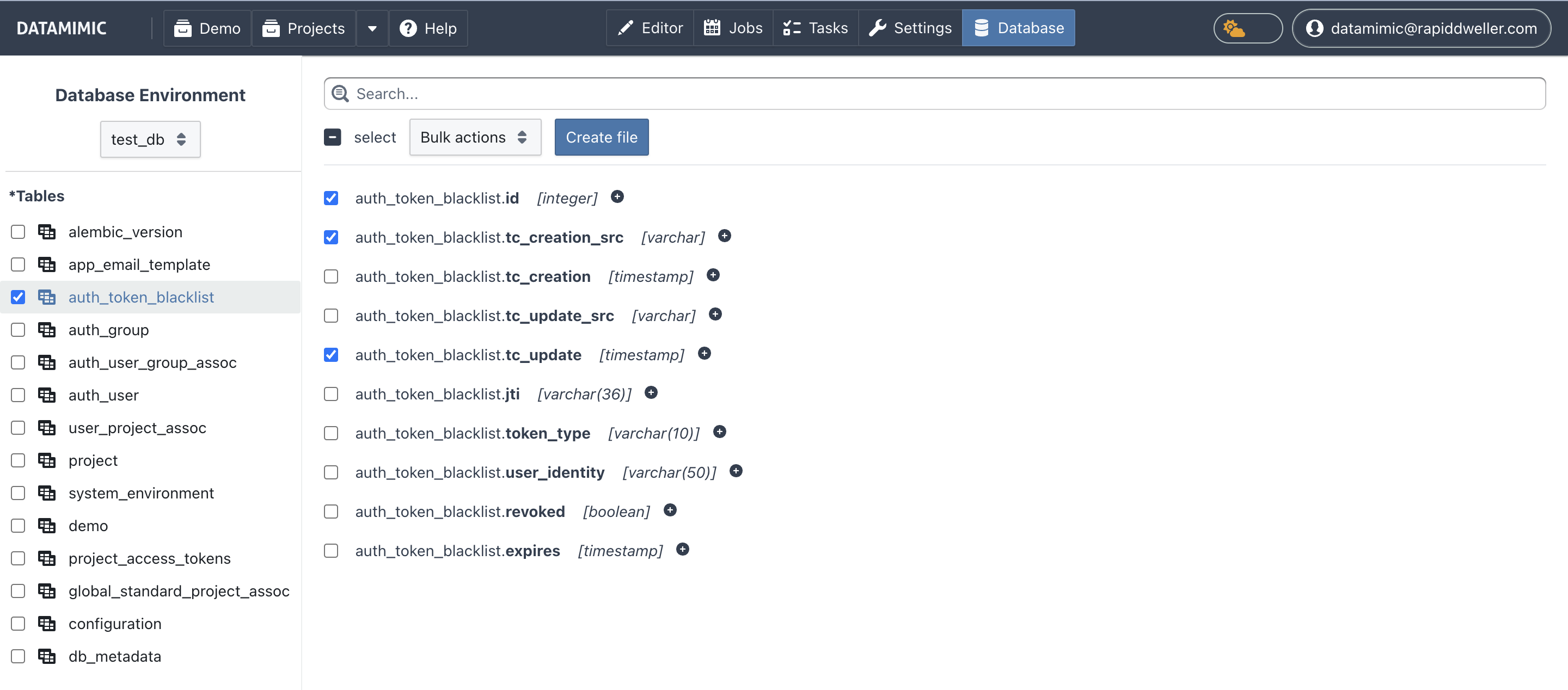
5. Erstelle Modell-Artefakte aus der Workbench¶
Nutze Generate artifacts im Planning-Tab.
A. Create Synthetic (.xml)¶
- Klicke Create Synthetic.
- Vergib einen Modell-Dateinamen.
- Setze die Relationship-Quelle (datenbankbasiert oder generierte Weighting-Dateien unter
data/). - Aktiviere optional schemaqualifizierte Namen.
- Aktiviere optional SQL-Schema-Skript-Export (
.scr.sql), falls für den Target-Setup benötigt.
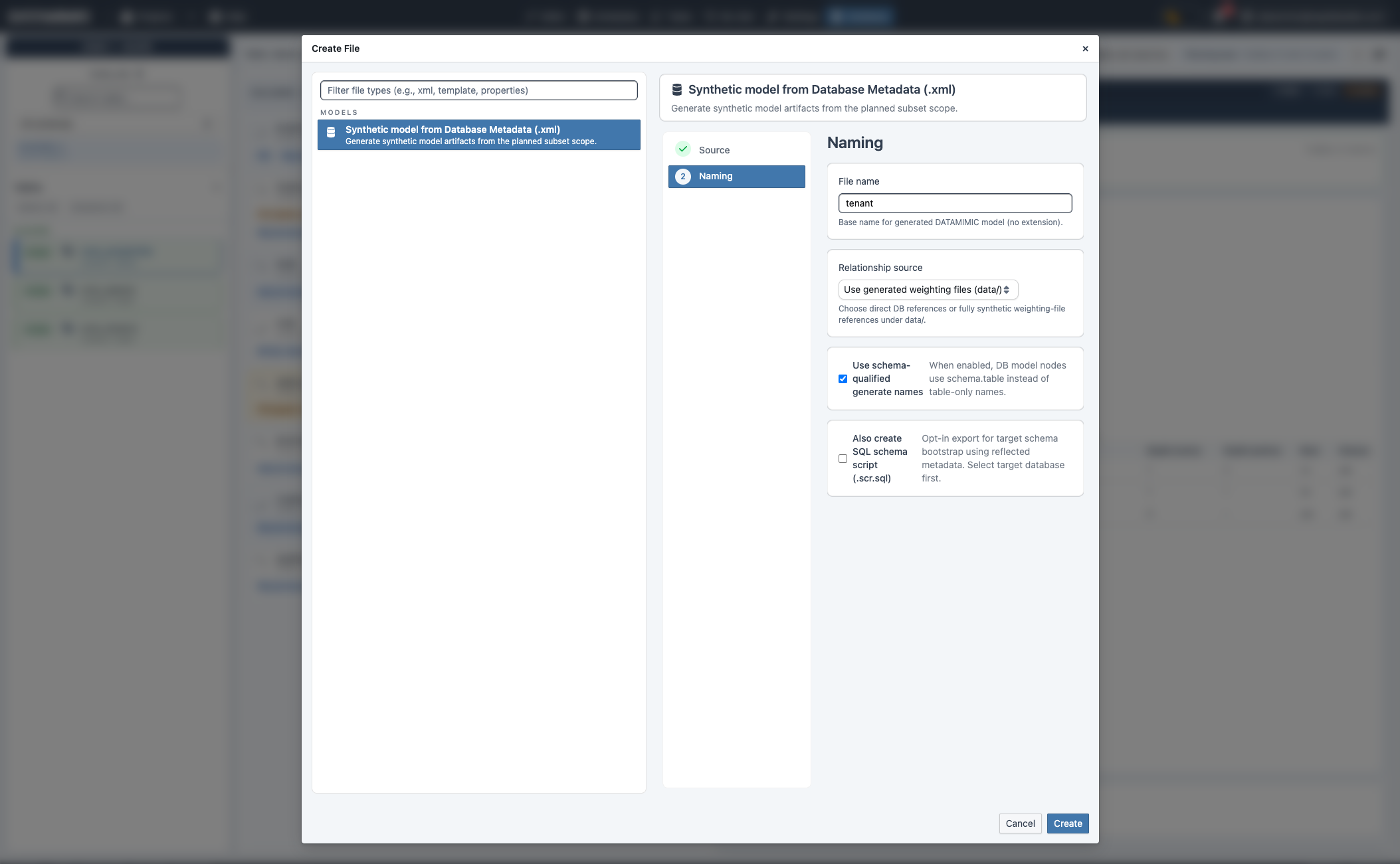
B. Create Anonymize (.xml)¶
- Klicke Create Anonymize.
- Prüfe Source-Datenbank und wähle die Target-Datenbank.
- Optional: PII-Preselect vor dem Erstellen anwenden und Threshold setzen.
- Zur Namensvergabe wechseln und Artefakt erstellen.
C. Create ML (.xml)¶
- Klicke Create ML.
- Prüfe die Source.
- Vergib Dateinamen und aktiviere optional schemaqualifizierte Namen.
- Erstelle das Modell-Artefakt.
- Führe das erzeugte DSL-Modell aus, damit
<ml-train>die ML-Generator-Versionen trainiert und persistiert.

Nächster Schritt: nach abgeschlossenem Trainingslauf Generator-Versionen und Qualitätsmetriken in der ML-Generator-Ansicht validieren und freigegebene Modelle anschließend mit source="ml://..." wiederverwenden, wie in ML-Generator aus Datenbank-Metadaten beschrieben.
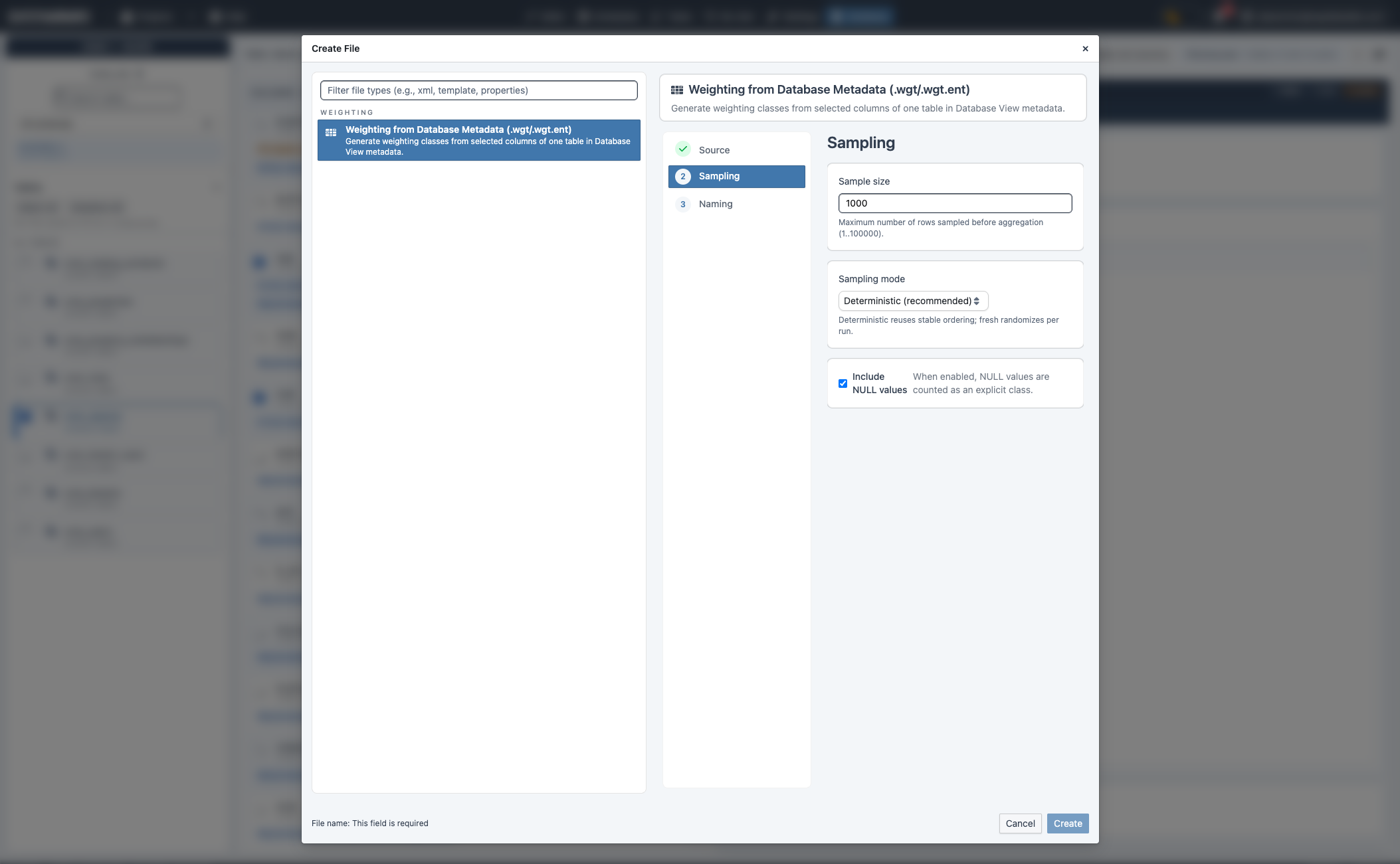
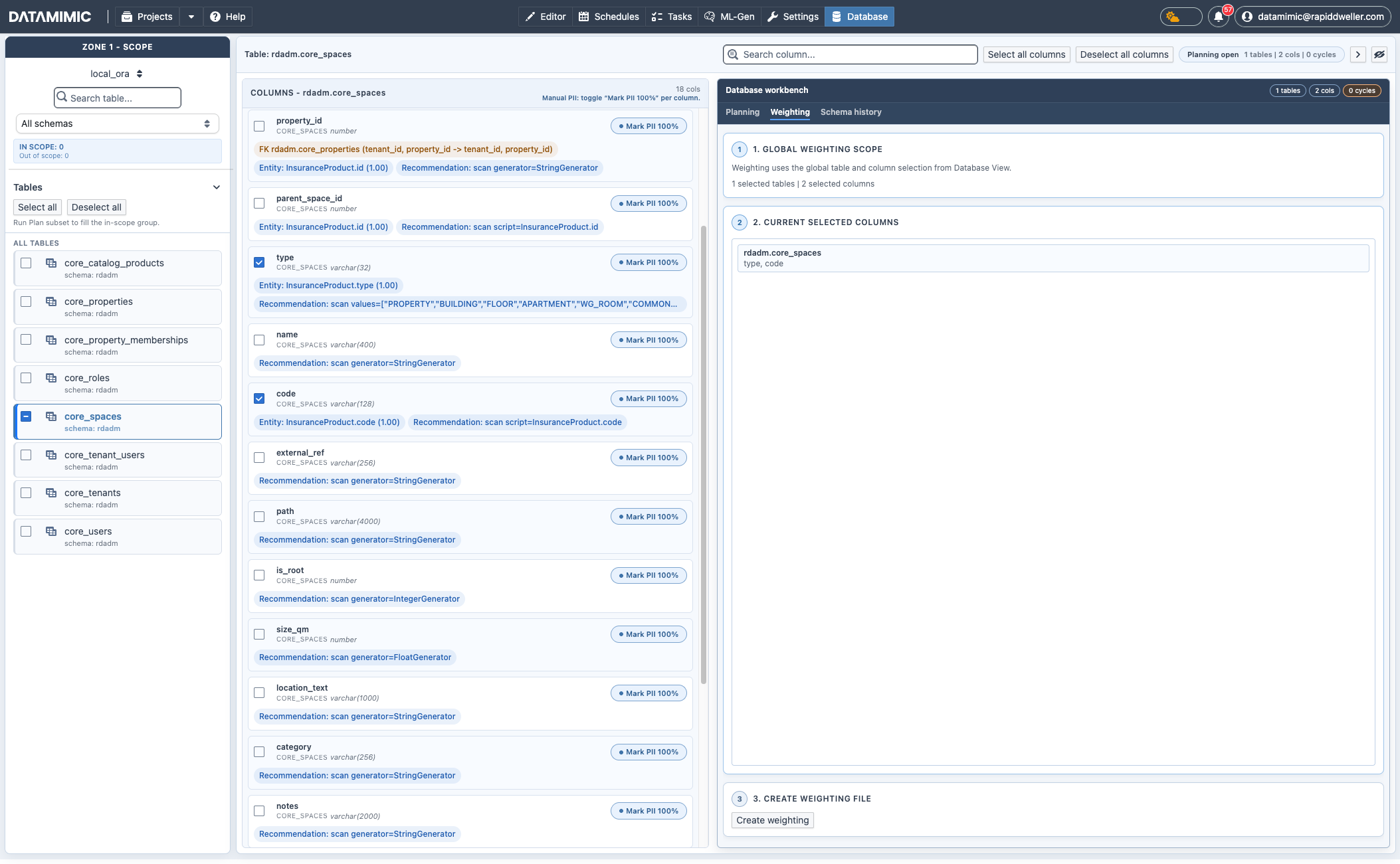
6. Erstelle Weighting-Artefakte im Weighting-Tab¶
Wechsle zu Database workbench → Weighting:
- Wähle genau eine Tabelle und eine oder mehrere Spalten im Metadaten-Scope.
- Prüfe die gewählten Spalten im Weighting-Tab.
- Klicke Create weighting.
- Konfiguriere Sampling:
sample_size(Standard1000)sampling_mode(deterministicoderfresh)include_nulls(true/false)- Dateinamen setzen und erstellen.
Ausgabe:
- Eine ausgewählte Spalte →
.wgt.csv - Mehrere ausgewählte Spalten →
.wgt.ent.csv
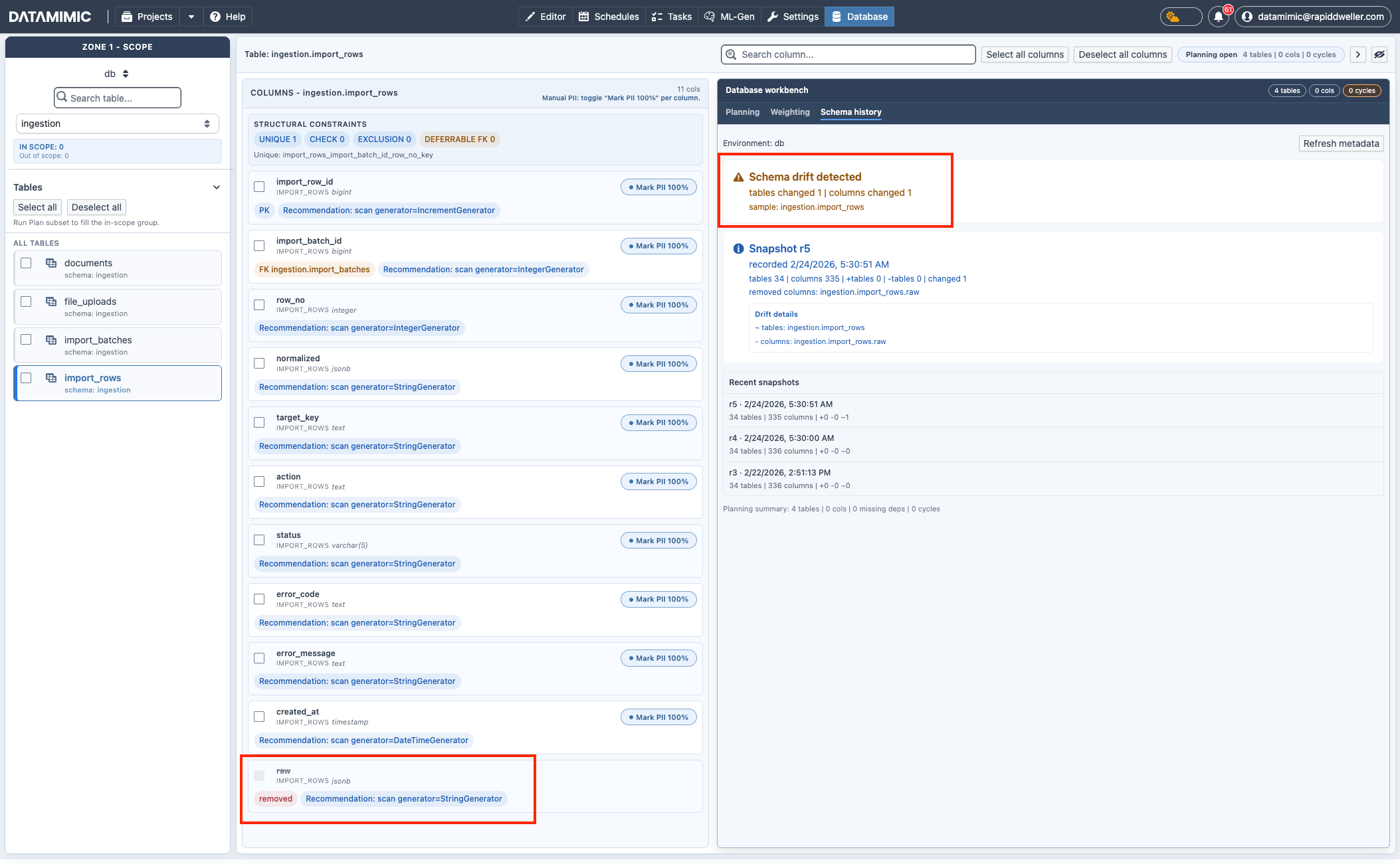
7. Schema Drift im Tab Schema history prüfen¶
Nutze Database workbench → Schema history, um erkannte Metadatenänderungen zwischen Snapshots zu prüfen, bevor du Artefakte neu erzeugst.
8. Erstellte Artefakte prüfen und verfeinern¶
- Modell-Flows erzeugen neue DATAMIMIC-Modell-Dateien (
.xml). - Weighting-Flow erzeugt Weighting-Dateien (
.wgt.csvoder.wgt.ent.csv). - Die weitere Verfeinerung erfolgt im Editor (Schlüssel, Generatoren, Skripte, Konverter, Targets).
Typische erzeugte <reference>-Ausgaben aus dem metadatenbasierten Datenbank-Flow:
1 2 3 4 | |
1 2 3 4 | |
9. Realistische Erwartungen an Empfehlungen setzen¶
- Empfehlungen aus der Datenbankansicht sind unterstützend und werden kontinuierlich verbessert.
- Für komplexe Schemata und produktive Anonymisierungsszenarien ist manuelle Nachbearbeitung der erzeugten Modelle zu erwarten.
- Nutze projektspezifische Review-Kriterien, um PII-Entscheidungen, Relationship-Handling und fachliche Randbedingungen vor dem Rollout zu validieren.
- Plane iterative Härtungszyklen ein, wenn sich Metadaten oder Quellschema ändern.
Für die vollständige <reference>-Semantik und Mapping-Priorität siehe Datendefinitionsmodell - Fortgeschrittene Elemente.