ML-Generator aus Datenbank-Metadaten¶
Diese Anleitung beschreibt den End-to-End-Flow: ML-Trainings-DSL-Artefakte aus Datenbank-Metadaten erzeugen, Training ausführen, persistierte Versionen in der ML-Generator-Ansicht prüfen und anschließend in der DATAMIMIC-DSL wiederverwenden.
Voraussetzungen¶
- Konfiguriere eine Datenbank-Umgebung unter Environments.
- Führe den Metadaten-Scan für diese Umgebung aus.
- Öffne die Datenbankansicht und stelle sicher, dass Tabellen/Spalten verfügbar sind.
1. ML-Trainings-Artefakt in der Datenbankansicht erstellen¶
- Wähle im Bereich Database workbench → Planning den Scope.
- Führe Plan subset aus (Preset-basierte Closure + Relationship-Validierung).
- Prüfe den Preflight-Status.
- Klicke in Generate artifacts auf Create ML.
- Setze Namensoptionen und erstelle das Modell-Artefakt.
- Führe das erzeugte DSL-Modell (mit
<ml-train>-Knoten) aus, um Training zu starten und Modellversionen zu persistieren.
Details zu Planung und Scope findest du unter Automatisches Generieren eines Modells aus einer Datenbank.
Note
Die Trainingsdauer hängt von Tabellengröße, Feature-Komplexität und Runtime ab. Größere Trainingsläufe können mehr CPU/RAM und je nach Setup auch GPU-Ressourcen (zum Beispiel NVIDIA-Karten) benötigen.
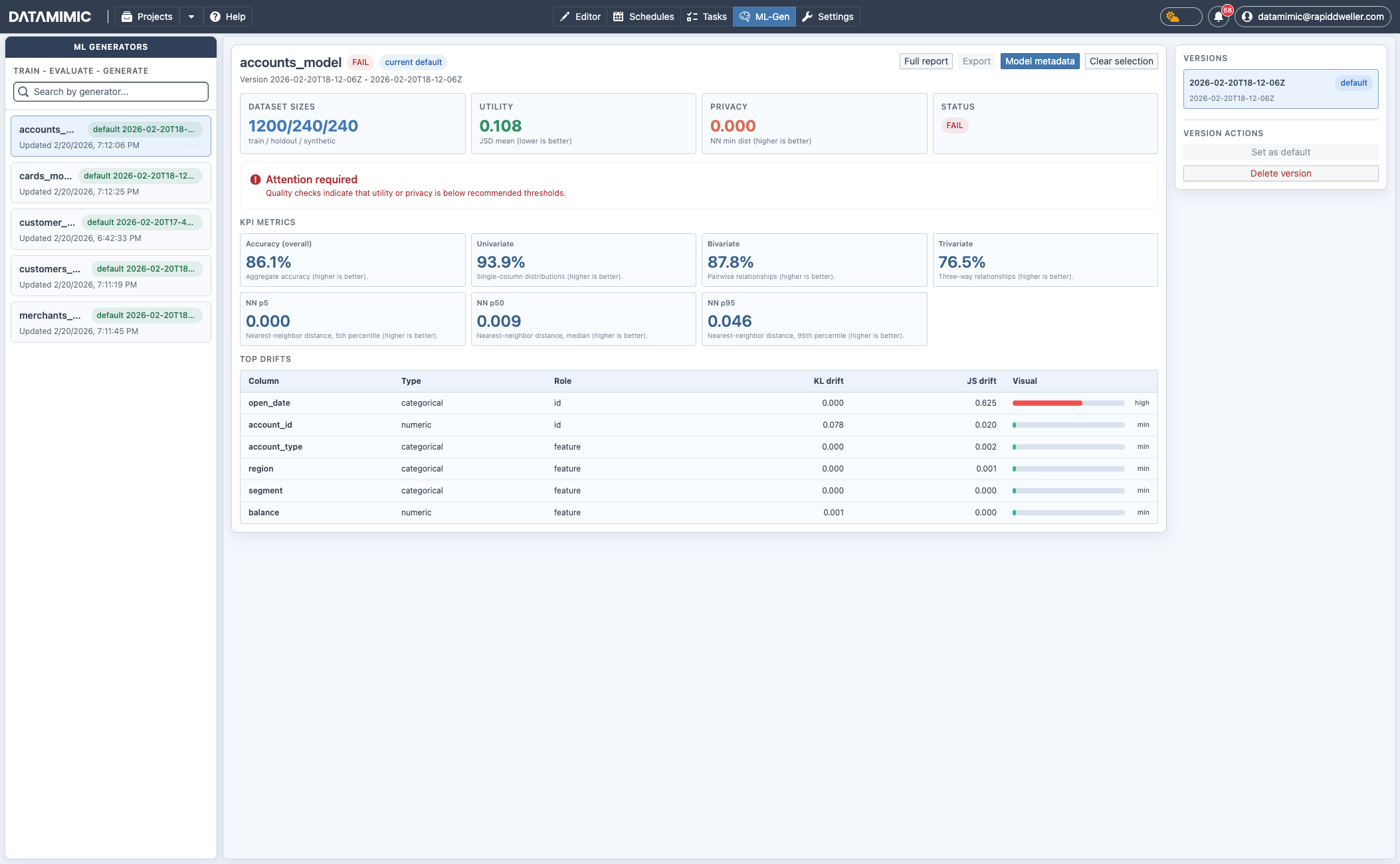
2. Qualität und Versionen trainierter Modelle in der ML-Generator-Ansicht prüfen¶
Öffne ML-Gen über die obere Navigation.
Nur Modelle mit abgeschlossenem und persistiertem Training werden hier mit Versionen und Statistiken angezeigt.
Dort kannst du:
- Generatoren links suchen und auswählen,
- zwischen Versionen wechseln,
- eine Version als Default setzen,
- veraltete Versionen löschen,
- Status, Utility/Privacy-KPIs und Drift-Indikatoren prüfen,
- Full report, Export und Model metadata verwenden.
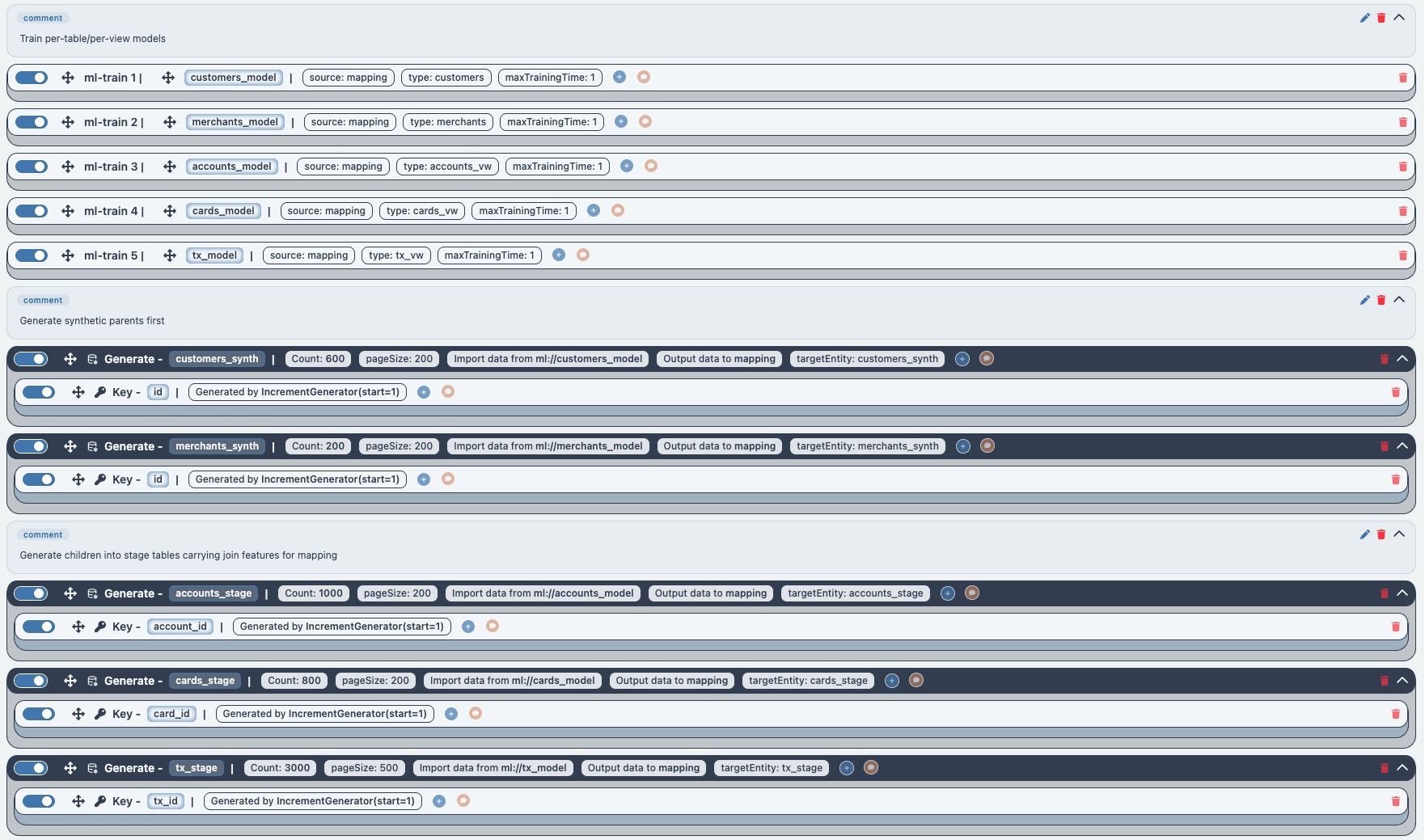
3. ML-Generatoren in der DATAMIMIC-DSL wiederverwenden¶
Nach Training/Persistierung kannst du Modelle als Quelle in <generate> mit ml://... referenzieren.
1 2 3 4 5 | |
Operative Hinweise¶
- Nutze stabile Subset-Planungsinputs für reproduzierbares Trainingsverhalten.
- Pflege pro Generator eine validierte Default-Version für nachgelagerte DSL-Nutzung.
- Trainiere neu, wenn sich Schema oder Datenverteilung relevant ändern.
- Prüfe Utility/Privacy-Status, bevor du eine Version als Default setzt.
- Betrachte erzeugte Empfehlungen und Modelle als Baseline, die projektspezifisch nachjustiert werden muss.