Workbench¶
Overview¶
The Workbench is the project-level home for connecting to a data source, scanning its structure, reviewing what was found, and generating DATAMIMIC artifacts from the result. It brings relational databases, MongoDB, and object storage together under one entry point.
Open it from the top navigation via Workbench.
The Workbench adapts to the selected environment — its Mode is derived from the environment type:
| Environment type | Workbench mode | What it does |
|---|---|---|
| Database (SQL) | Database | Metadata-driven scope planning, weighting, schema-drift visibility, and synthetic / anonymize / ML generation. This is the Database View, now hosted inside the Workbench. |
| MongoDB | Mongo | Scan a collection, review the inferred fields, and generate a model. |
| Object storage | Object Storage | Scan CSV, JSON, or Parquet objects, review the inferred fields, and generate a model. |
What changed in 3.5.0
The Database View is now part of the Workbench (Database mode) for SQL environments — it is the same metadata-driven flow, reached through the Workbench rather than as a separate view. The Workbench also adds two new modes, Mongo and Object Storage, so scanning is no longer limited to relational databases.
Create the matching environment first under Settings → Environments.
Database mode (SQL environments)¶
For a database environment, the Workbench opens the Database View: scope selection (Zone 1), the Planning, Weighting, and Schema history tabs, subset dependency preflight, and the Create Synthetic, Create Anonymize, and Create ML actions.
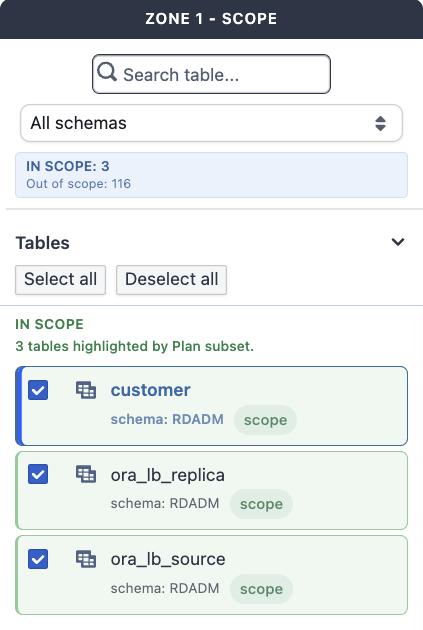
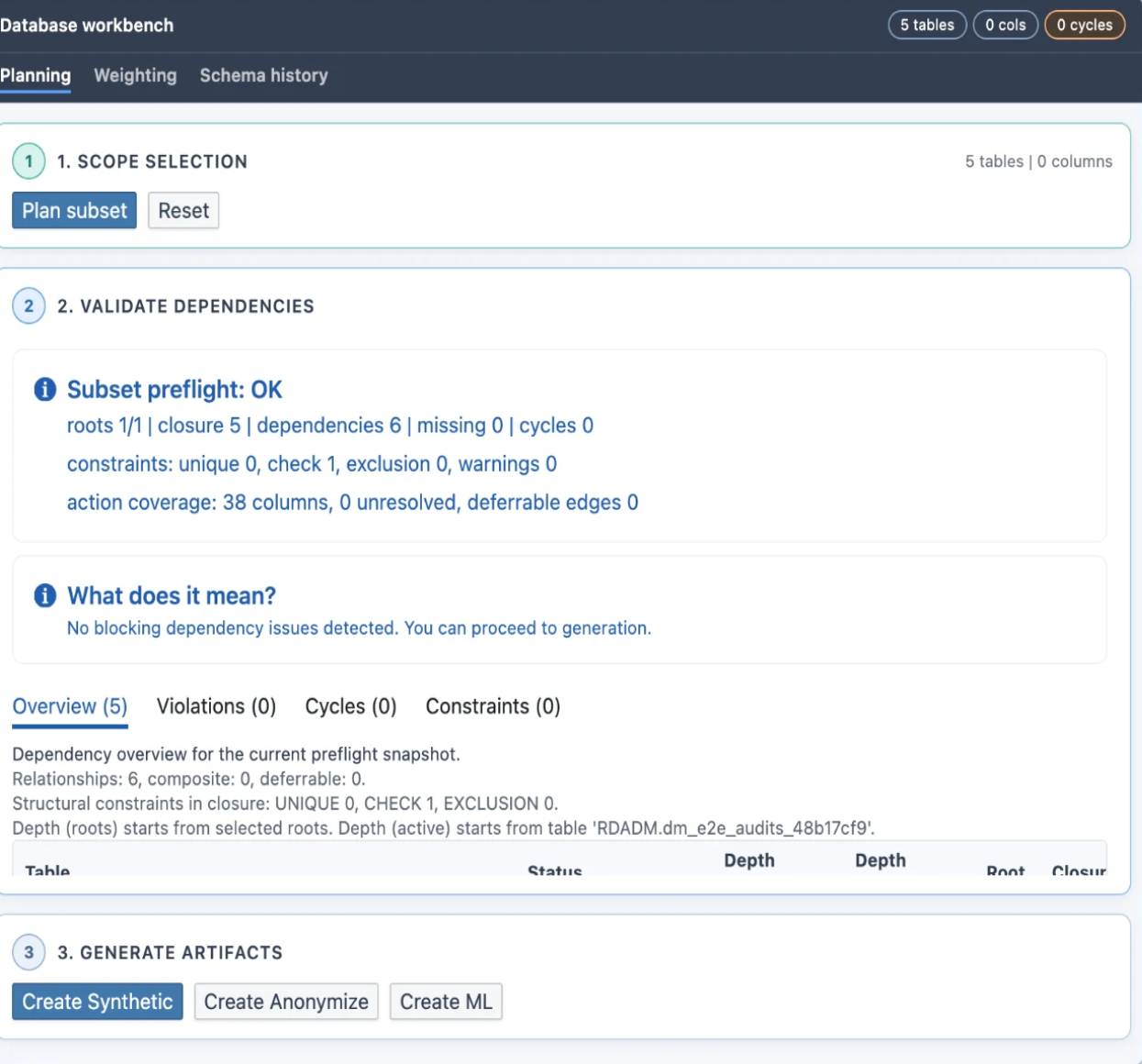
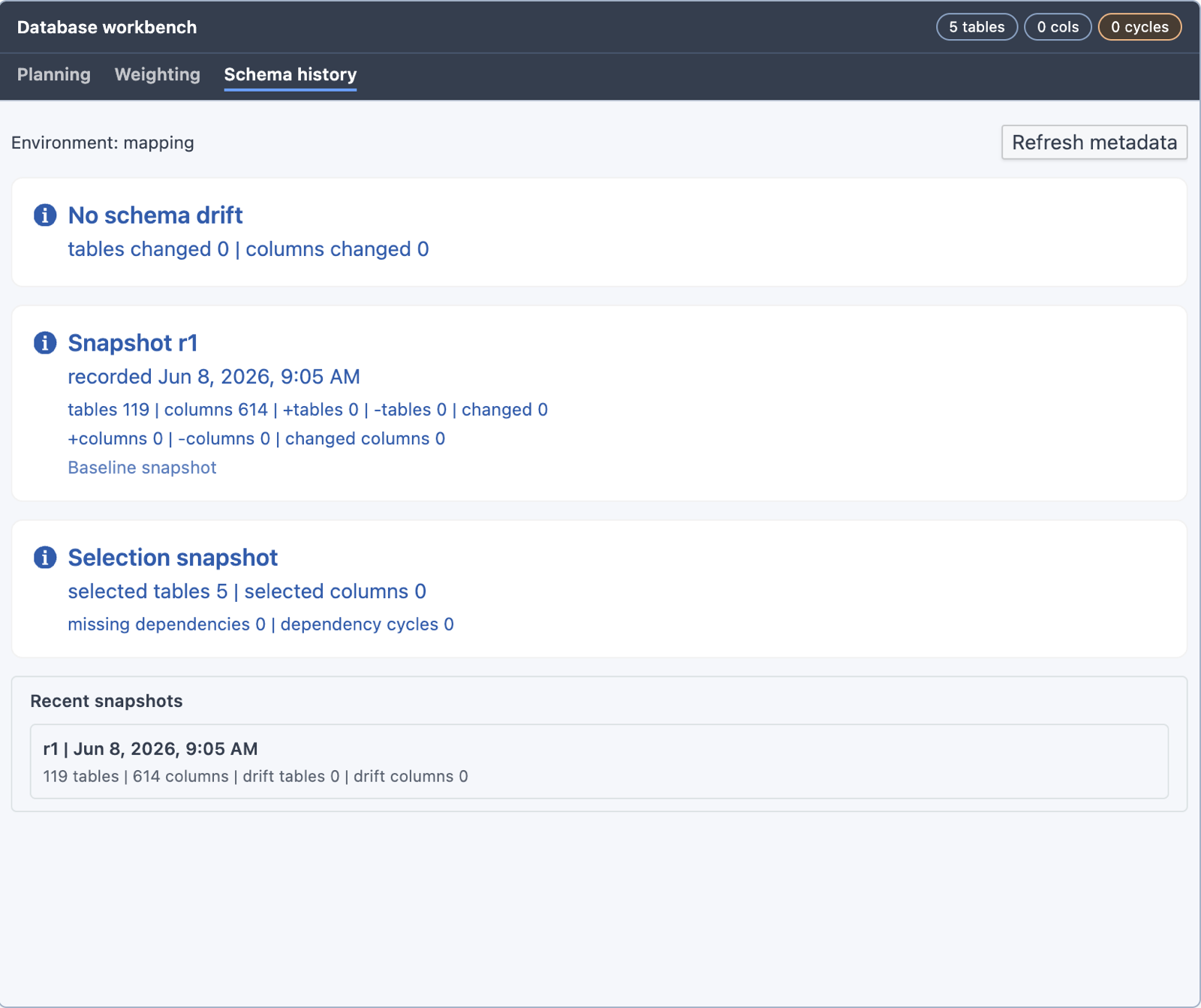
This is the same flow documented in detail under Database View; it is now reached through the Workbench instead of as a standalone view.
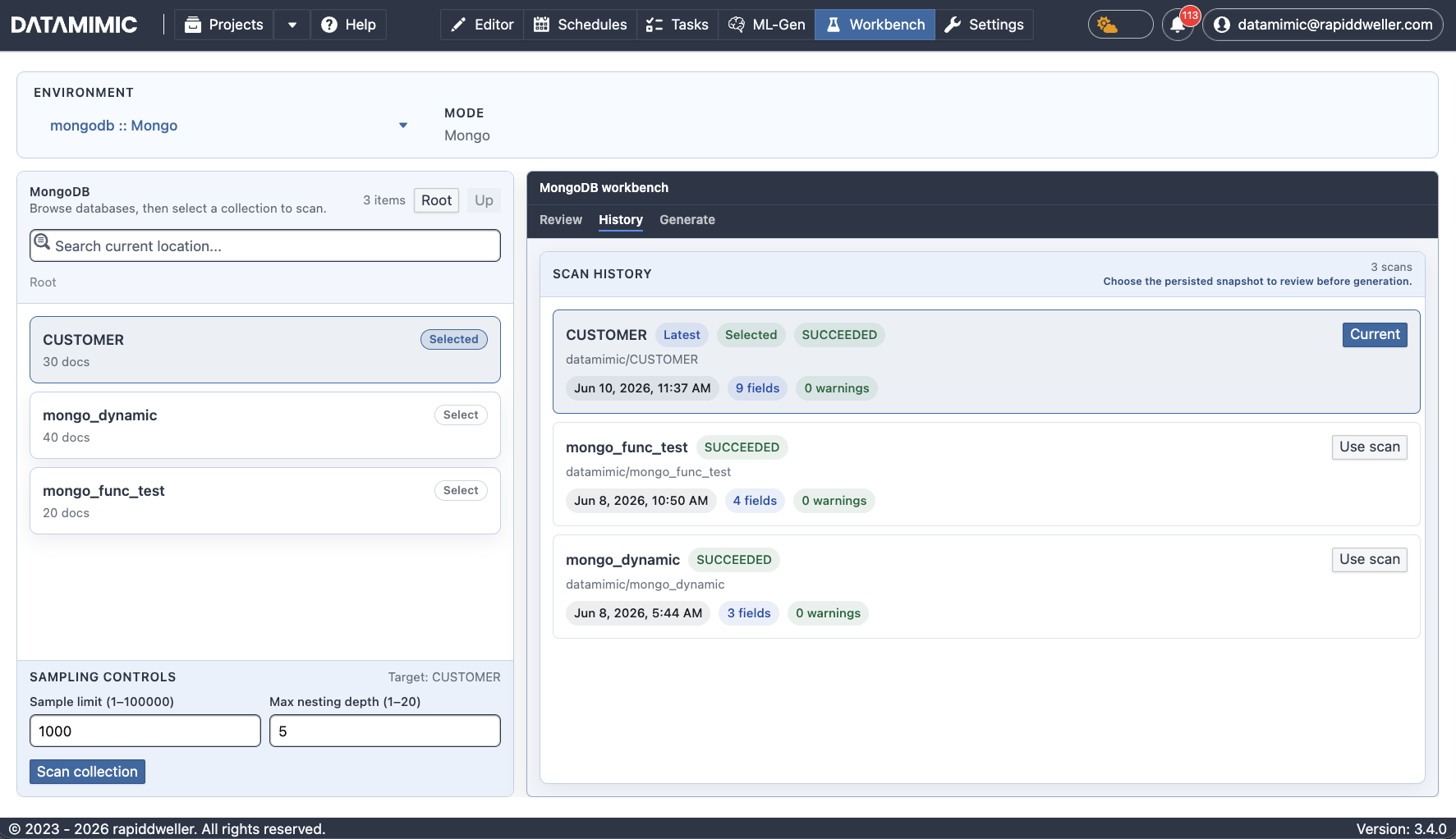
Mongo mode (MongoDB collections)¶
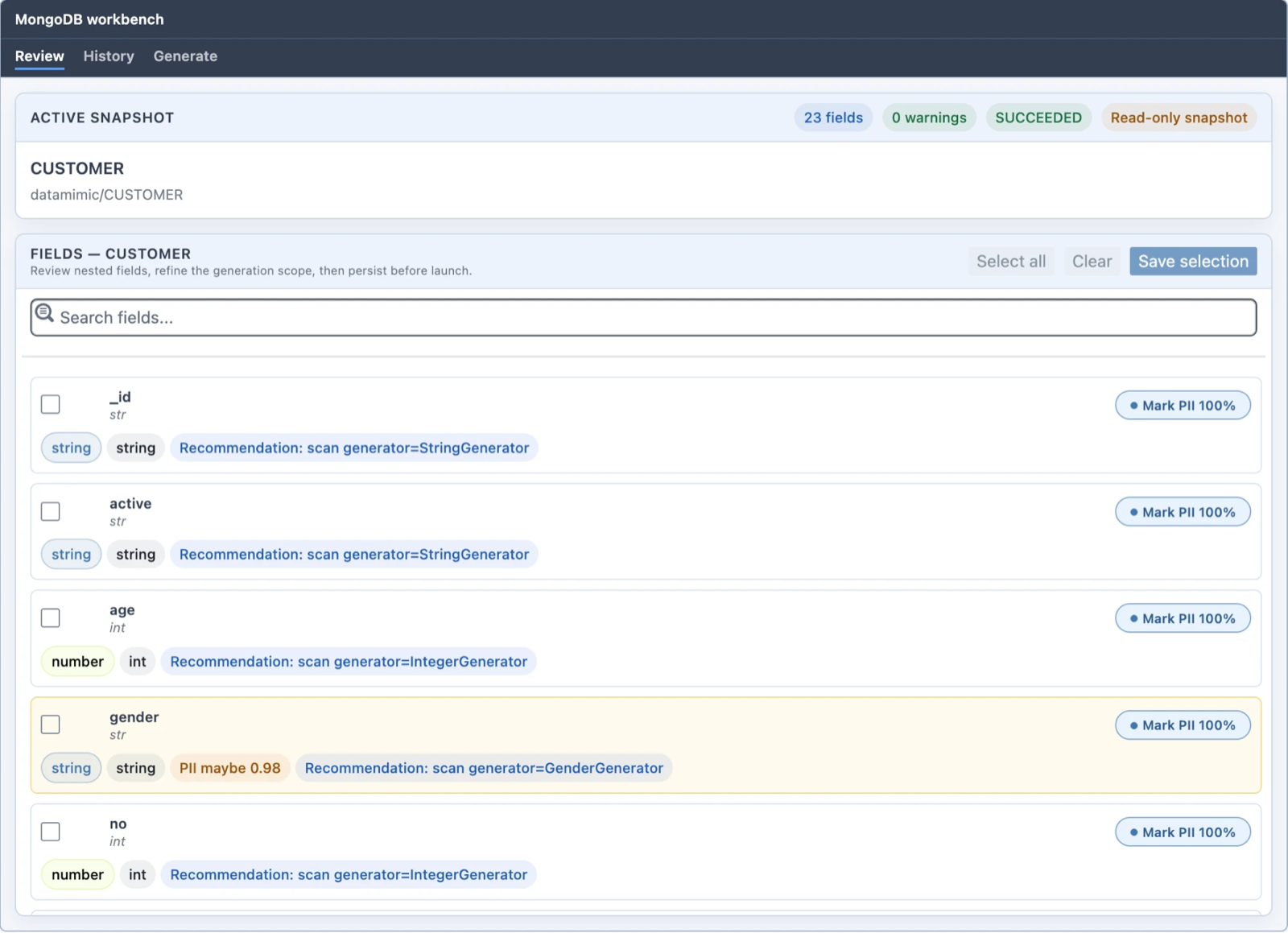
- Left pane — browse databases and collections (use Root / Up and the search box), then Select a collection as the scan target. Sampling Controls offer Sample limit (1–100000) and Max nesting depth (1–20); Scan collection runs the scan and persists a snapshot.
- Right pane — three tabs over the scan result:
- Review — the active snapshot's fields with inferred type, a generator recommendation (for example,
scan generator=StringGenerator), and a Mark PII control. Select fields, search, and Save selection to persist the generation scope. - History — persisted snapshots with timestamp, field count, warnings, and status; Use scan loads one back into Review.
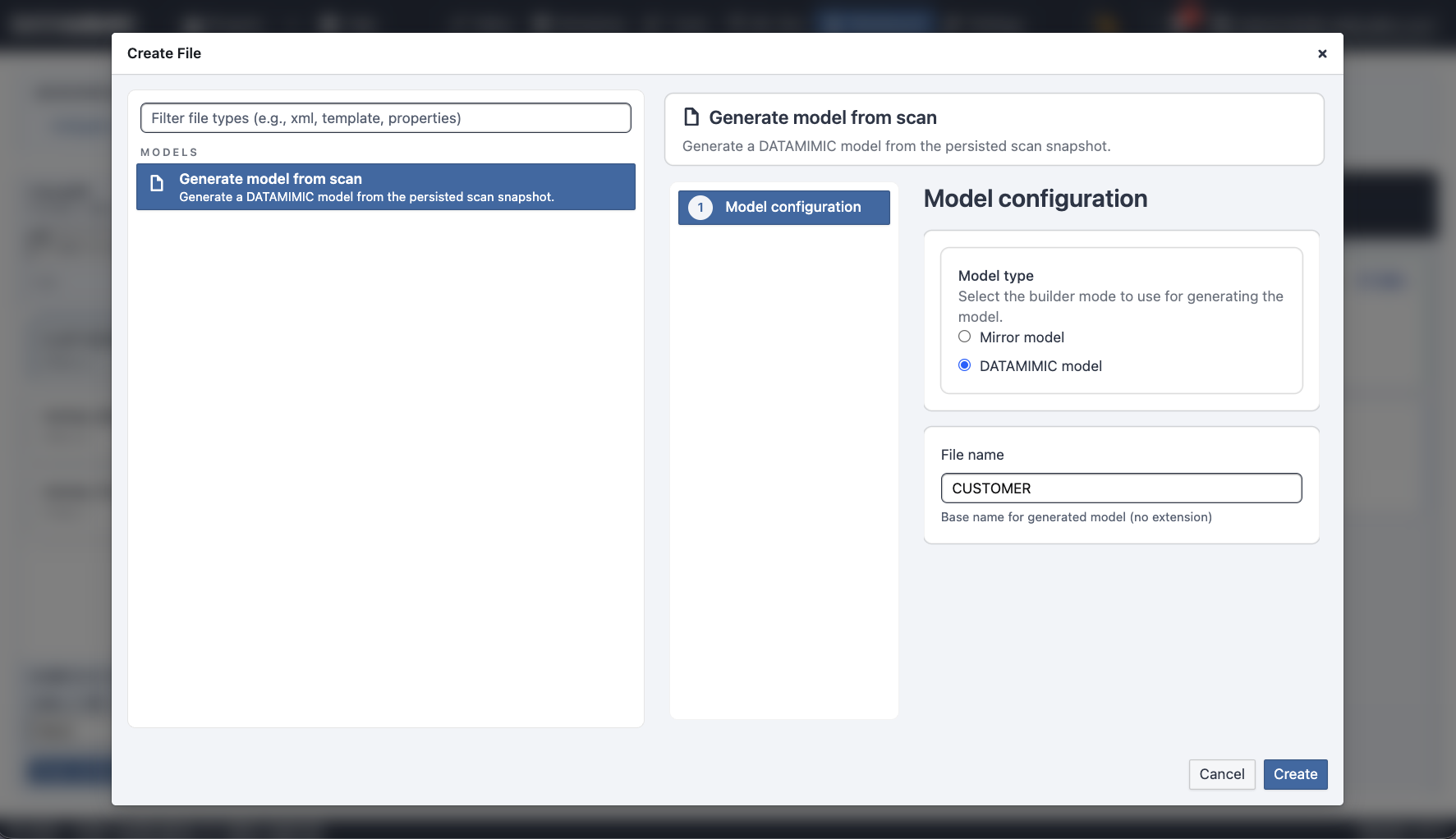
- Generate — the Create File → Generate model from scan dialog, where you pick a Mirror model (structural mirror) or a DATAMIMIC model (full model assembled from the scan and your selections), set a file name, and Create it into the project.
- Review — the active snapshot's fields with inferred type, a generator recommendation (for example,
Object Storage mode (CSV / JSON / Parquet)¶
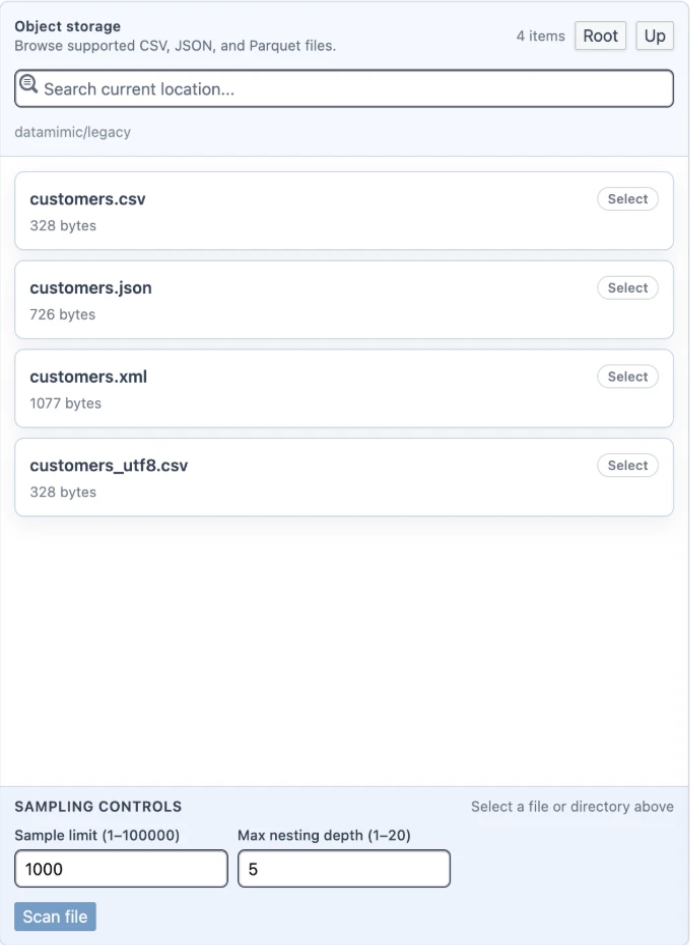
Object Storage mode works like Mongo mode, with a few specifics:
- Browse supported CSV, JSON, and Parquet files.
- Sampling Controls add Max partition bytes (≤2 GiB) for Parquet inputs.
- Scan a single file with Scan file, or a directory as a Parquet dataset.
- Review, History, and Generate behave as in Mongo mode.
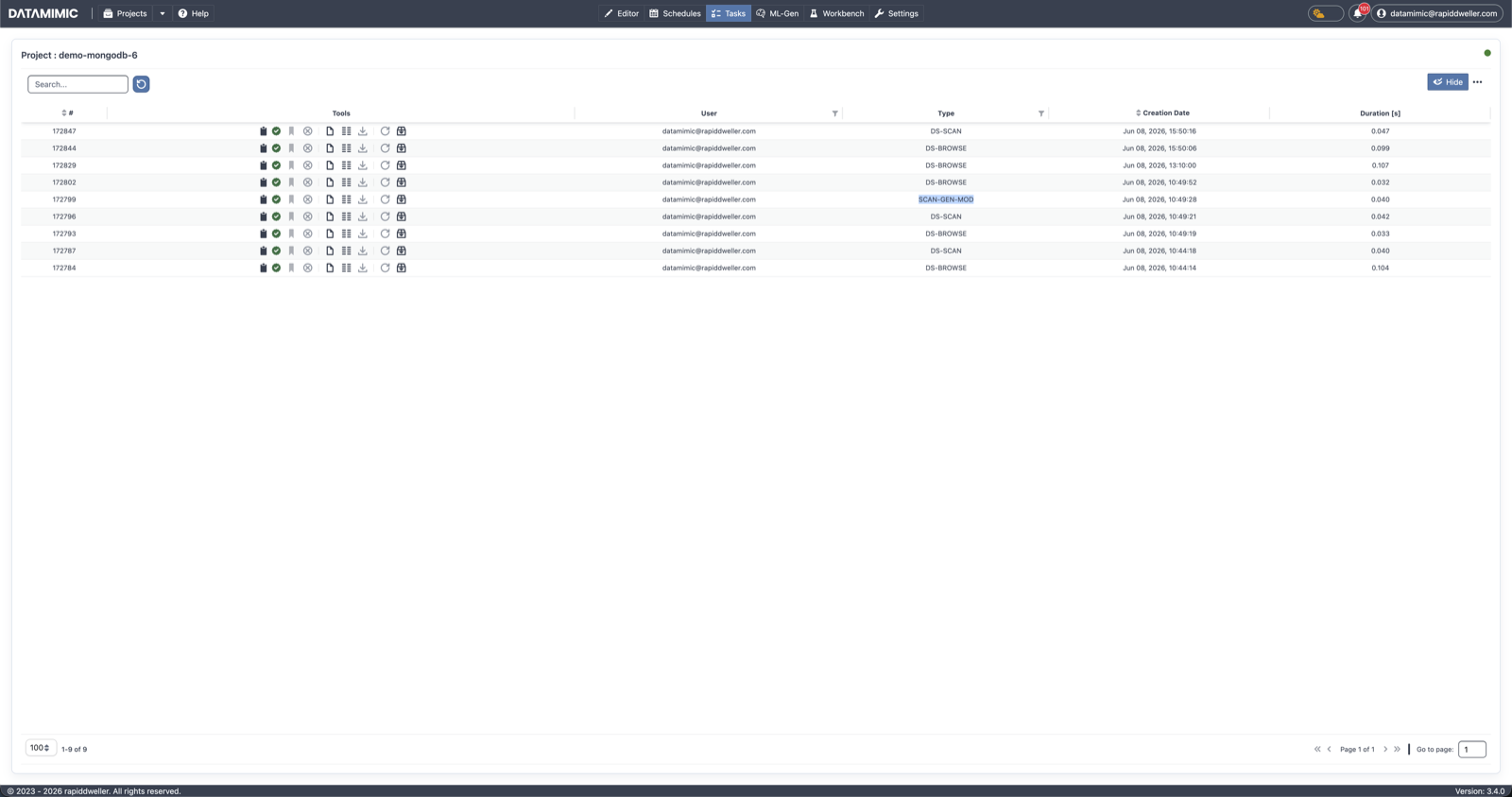
Scan steps in TaskView¶
Workbench browse, scan, and generation run as background data-source tasks, visible in Tasks:
- DS-BROWSE — browse a source location (databases, collections, directories, or files).
- DS-SCAN — scan the selected table, collection, or object into a snapshot.
- SCAN-GEN-MOD — generate a model from a persisted scan snapshot.
Typical Flow (Mongo and Object Storage)¶
- Select a Mongo or Object Storage environment.
- Browse to the collection or object and Select it.
- Set the sampling controls, then run the scan.
- In Review, refine fields, mark PII, and Save selection.
- Optionally switch snapshots from History.
- Generate a Mirror or DATAMIMIC model and open it in the Editor.
For SQL databases, follow the planning, weighting, and generation flow in Database View.
Note
Scans are sampled and persisted as snapshots — re-scan to refresh. Field selections and PII marks are saved with the snapshot and feed the generated model.